人工智能合同法(上):导论

多年来,人们渴望产品中含有"真实"成分——比如纯正牛奶、天然奶酪、原汁果汁和纯正培根。但世界已然改变——如今人们更青睐人造产品:人造肉、人造皮草,当然还有人工智能(简称AI技术或AI)。 从苹果的Siri®、亚马逊的Alexa®、微软的Cortana®等虚拟助手,到家电领域运用AI技术为消费者烹制完美晚餐,再到IBM的Watson®助力新药研发——无论消费者还是企业,似乎都对"内置AI"的产品与服务展现出永不满足的渴求。 对企业而言,人工智能的应用正迅速从竞争优势转变为必备业务流程;对消费者而言,它则承载着简化生活、提升舒适度的美好期许。
人工智能的蓬勃发展实属必然。科技进步使人工智能产品日益普及且价格亲民,这些产品能够执行传统上需要人类运用自身智慧完成的任务。与此同时,相关技术正以惊人速度向前发展,朝着能够与人类智能相媲美的通用人工智能系统迈进。人工智能不仅已深入人心,更将成为商业运营中日益重要的组成部分。
然而,许多企业仍然认为,开发或使用人工智能产品与服务的合同签订方式应与传统软件产品及服务的合同签订方式相同。毕竟,尽管基于硬件的架构正日益普及——这类架构能加速人工智能中许多基础操作的运行——但部分人工智能产品完全由软件构建而成。那么,为何开发或使用人工智能产品与服务的合同签订方式不能与其他类型软件产品及服务的合同签订方式保持一致? 虽然复杂的解答留待后续讨论,但简单来说,人工智能技术的特性与设计方法论与传统软件截然不同,因此在签订人工智能产品与服务合同时涉及的法律问题,与传统软件合同中出现的问题存在根本差异。 若按传统软件合同模式签订人工智能技术合约,往往导致双方(供应商与用户)提出不合理要求,对各类数据价值及双方开发人工智能产品所需的重要技术诀窍产生过度或低估的评估。这使得人工智能合同谈判屡屡受挫。 本系列文章将深入探讨这些差异的本质、成因及应对策略。
不同类型的人工智能技术
“人工智能”或“AI”这两个术语常被用作“机器学习”技术的通用名称。 机器学习旨在通过在特定数据类型中发现特定规则,并基于这些推导出的规则对其他数据进行推理或预测,从而"教导"计算机完成各类任务。该技术采用归纳法基于实际观测事件(即数据)发展规则,而非传统软件常用的演绎法。深度学习作为机器学习的子类别,试图通过神经网络实现更精确的推理。 神经网络通过大量小型处理器间的紧密互联,试图模拟人类大脑的处理机制。尽管此类学习传统上在图形处理器(GPU)上实现——因GPU具备多处理单元与高连接性的相似特性——但近年来专为人工智能设计的处理器已陆续问世并持续研发中。
传统软件开发与人工智能技术开发之间的差异
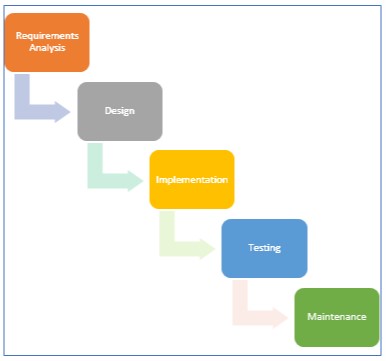
自计算机诞生以来,传统软件的开发始终遵循演绎式流程,通常采用"瀑布式"开发模型。 对软件开发者而言,任务相对简单:首先依据已知规则(算法)详细定义软件规格,随后进行软件设计、实现、测试及逐步优化,直至所有预期功能实现且规则得到满足。典型传统软件开发流程如下所示。通常情况下,除因测试发现缺陷而对设计或实现进行局部优化外,逆向推进流程的情况较为罕见。
然而,人工智能技术——尤其是机器学习的发展——基于的是一个根本不同的概念。机器学习是一种训练方法,旨在通过输入和输出数据(或事件)来发现特定规则,并基于这些推导出的规则对用户数据进行推断和预测。这一过程通过使用归纳开发方法实现,该方法利用实际观测到的输入和输出数据,通常无需理解任何导致输入产生输出的规则或算法。 具体流程包括:分析目标需求,尝试初始AI架构与参数设置,测试结果,并重复此过程直至获得预期效果。这通常需要大量试错来理解数据集特性,并不断调整AI处理单元的结构与参数直至目标达成。下图展示了AI技术的典型开发流程。
|
传统软件开发
|
人工智能技术开发流程
|

人工智能技术合同签订中的挑战
机器学习的归纳特性为合同签订带来了某些独特问题,使其有别于传统软件的合同签订。然而存在一个相似点——单纯使用已开发的人工智能与供应商为特定方专门开发人工智能相比,会引发不同的关注点,因而需要不同的合同处理方式。但相似性通常止步于此,传统软件与人工智能技术之间的本质差异开始为合同签订带来挑战。主要挑战包括:
- 人工智能模型的结果未必始终准确,而应容忍一定比例的误差。由于人工智能技术基于具有特定统计特性的训练数据推导规则,再将其应用于统计特性可能略有差异的未知数据,因此其输出结果偶尔可能出现偏差。这与传统软件存在本质差异——传统软件要求符合严格定义参数的数据必须100%产出正确结果,而超出参数范围的数据则应被拒绝。因此,人工智能模型的规格通常以错误率作为衡量标准。
- 供应商提前提供性能保证面临的挑战:由于人工智能技术的发展高度依赖训练数据集,供应商在签约时难以预知该技术在合同执行阶段应用于用户数据集时的表现。 若训练数据集与用户数据的统计特性存在显著差异——包括训练数据未涵盖统计学上的罕见事件——该AI模型在投入实际应用后可能最终失效。
- 验证人工智能模型极其困难:传统软件若未达到预期性能,通常可通过反复验证和修改软件来找出根本原因并加以修正。而人工智能技术的构建过程,人类却难以理解其运作机制。 因此当AI表现未达预期时,难以判断根本原因究竟源于训练数据质量、神经网络结构或初始参数设置,抑或是传统软件/硬件缺陷导致的偏差。
- 与传统软件开发不同,人工智能模型的开发本质上是一个反复试验的过程:人工智能技术协议的各方应预期供应商将投入大量资源(通常以人力形式)来处理或调整数据,以寻找能够实现预期结果的正确模型结构和参数。
- 人工智能模型的内容与性能高度依赖于训练数据:人工智能的训练过程及其最终生成的结果,很大程度上取决于训练数据与实际使用数据相比的统计特性。通常而言,要从训练数据集中消除所有统计偏差极为困难甚至不可能,且这些训练数据集往往不包含统计学上的罕见事件。 此外,其设计假设是训练数据与使用数据的统计特性基本一致。因此,若两者统计特性存在差异——尤其当使用数据包含罕见事件时——便可能产生错误或意外结果。这不仅可能导致AI模型失效,还迫使供应商为不同用户开发不同版本的AI系统。
- 在创建和使用人工智能模型时,专业知识的价值尤为突出:尽管 传统软件开发也需要一定程度的专业知识,但在人工智能技术开发过程中,专业知识往往更为关键。例如,与创建训练数据和设定人工智能初始参数相关的专业知识,对于确保人工智能不仅满足需求,而且在统计学上足够精确——既能准确反映用户数据又将误差降至最低——具有重要意义。 训练数据本身的统计特性,可能源于用户或供应商经年累月运用传统方法处理数据所积累的专有技术。此外,由于人工智能技术的创建往往需要更多试错过程,以"下一步该尝试什么"为形式的专有技术,对于收敛至符合目标的人工智能尤为关键。
在本系列后续文章中,我们将深入探讨这些挑战对合同产生的影响。
结论
人工智能技术的开发与使用合同必须区别于传统软件的开发与使用合同。这主要源于人工智能技术开发具有归纳性质,而传统软件通常采用演绎过程。此外,人工智能模型的质量很大程度上取决于所使用的训练数据——正如老话所说,垃圾输入,垃圾输出。 用户在签订合同时应充分认识这些差异,并准备调整其合同实践——从传统软件服务合同惯例转向……截然不同的模式。在后续系列文章中,我们将阐述人工智能技术开发与应用所需的关键要素,从用户和供应商双重视角解析这些要素的知识产权影响,并介绍可用于达成合理协议的合同制定方法。


